리소스 동적 관리란 무엇인가?
리소스 동적 관리는 IaC 코드를 사용하여 필요에 따라 리소스의 수를 조절하고 구성을 다양화하는 방법이다.
리소스의 수가 고정되지 않고 사용자의 입력에 따라 변경할 수 있다. Terraform과 같은 IaC 도구를 사용하면 코드의 재사용성이 향상되고, 구성의 복잡성이 줄어들며, 환경을 보다 유연하게 변경할 수 있게된다.
리소스를 동적으로 관리하고 생성하기 위해 기본적으로 count와 for_each 두 매개변수를 활용할 수 있다. 이 두 매개변수는 여러 인스턴스의 리소스를 생성하는 기능을 제공하지만, 그 사용법과 리소스 구성의 차이가 존재한다.
count 매개변수 사용
count 매개변수는 정수 값을 이용하여 지정된 수만큼 리소스 인스턴스를 생성할 때 사용된다. 이 방법은 주로 인덱스 기반의 간단한 반복 작업에 유용하며, 동일한 설정을 가진 여러 리소스를 생성할 필요가 있을 때 주로 사용한다. 간편하게 리소스의 개수를 조정할 수 있는 장점이 있다.
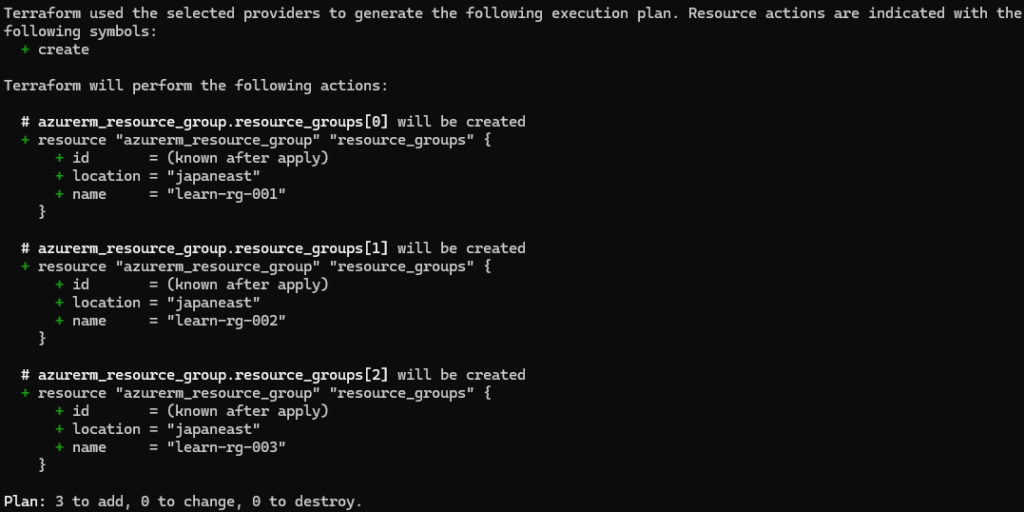
example. 1
리소스 그룹의 이름은 resource_group_name 변수와 count.index를 조합하여 동적으로 생성된다.
count.index는 0부터 시작하므로 count.index + 1을 사용하여 이름에 1부터 시작하는 숫자 부여한다. 이 숫자는 format 함수를 통해 세 자리 숫자 (001, 002, 003 ..) 로 포맷팅된다.
# Variables
variable "location" {
type = string
default = "Japan East"
}
variable "resource_group_name" {
type = string
default = "learn-rg"
}
variable "resource_group_count" {
type = number
default = 3
}
# Resource Groups
resource "azurerm_resource_group" "resource_groups" {
count = var.resource_group_count
location = var.location
name = "${var.resource_group_name}-${format("%03d", count.index + 1)}"
}example. 2
length 함수는 리스트, 맵, 또는 문자열의 길이나 요소의 개수를 반환하며, 리소스를 반복해서 생성하거나 조건부 로직을 구현하는 등 동적 인프라 구성에 사용된다.
예를 들어, resource_group_names라는 리스트에 리소스 그룹의 이름이 저장되어 있을 때, length 함수를 사용하여 이 리스트의 요소 수를 확인하고, 해당 수만큼 리소스 그룹을 생성할 수 있다.
# Variables
variable "location" {
type = string
default = "Japan East"
}
variable "resource_group_names" {
type = list(string)
default = [
"learn-rg-001",
"learn-rg-002",
"learn-rg-003"
]
}
# Resource Groups
resource "azurerm_resource_group" "resource_groups" {
count = length(var.resource_group_names)
location = var.location
name = var.resource_group_names[count.index]
}terraform plan 실행 결과
for_each
Terraform의 for_each 매개변수는 맵(map)이나 셋(set)과 같은 복잡한 데이터 구조를 활용해 리소스의 각 인스턴스에 서로 다른 구성을 적용할 때 사용한다. 이 매개변수를 사용하면 각 리소스에 고유한 식별자나 특별한 구성을 제공할 수 있어, 유연한 리소스 구성이 가능하지만 설정이 살짝 복잡해진다.
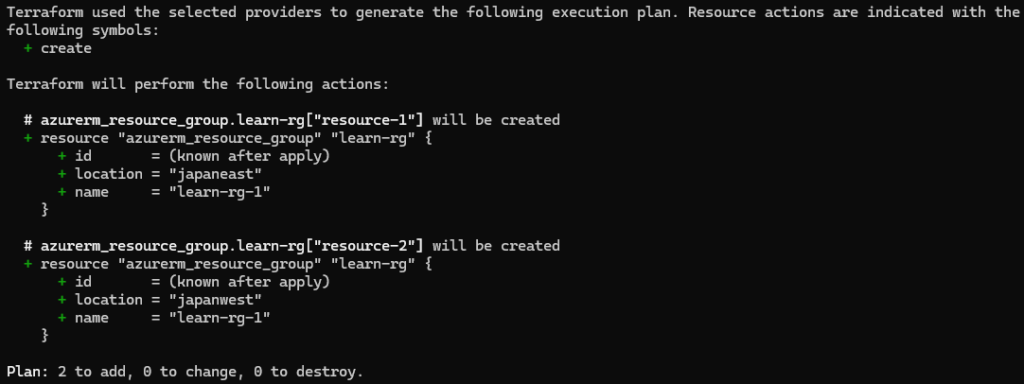
example. 1
각 리소스 그룹의 설정이 map 의 각 항목의 속성에 따라 독립적으로 할 수 있다. resource_groups 맵에 정의된 수만큼 리소스 그룹을 생성하고, 각 리소스 그룹의 설정 값은 맵에 지정된 값을 기반으로 생성된다. 코드의 중복을 줄이고, 여러 설정을 효율적으로 처리할 수 있다.
# Variables
variable "resource_groups" {
type = map(object({
location = string
name = string
}))
default = {
"resource-1" = {
location = "Japan East",
name = "learn-rg-1"
}
"resource-2" = {
location = "Japan West",
name = "learn-rg-1"
}
}
}
# Resource Groups
resource "azurerm_resource_group" "learn-rg" {
for_each = var.resource_groups
location = each.value.location
name = each.value.name
}terraform plan 실행 결과
count 와 for_each 어떤 것을 사용해야 하는가?
실제 사용 상황에서는 for_each 사용을 권장한다. 특히, 각 리소스 인스턴스가 고유한 식별자나 구성 요소를 가지고 있을 경우 더욱 그렇다. for_each 는 리소스의 특정 요소의 변경이나 제거가 다른 인스턴스에 영향을 미치지 않는다.
count 는 단순히 많은 수의 동일한 리소스를 빠르게 생성할 때 유용할 수 있지만, 관리적인 측면에서 대응하기 어려운 경우가 발생하기 쉽다. 리소스 배열에서 특정 인스턴스를 제거하면, 그 뒤의 모든 인스턴스가 새로운 인덱스를 받아 배포 시 모든 인스턴스가 재성성될 리스크가 존재한다. 상태 관리와 변경 관리를 복잡하게 만들 수 있으므로 사용하지 않는 것이 좋다고 생각한다.
example. 1
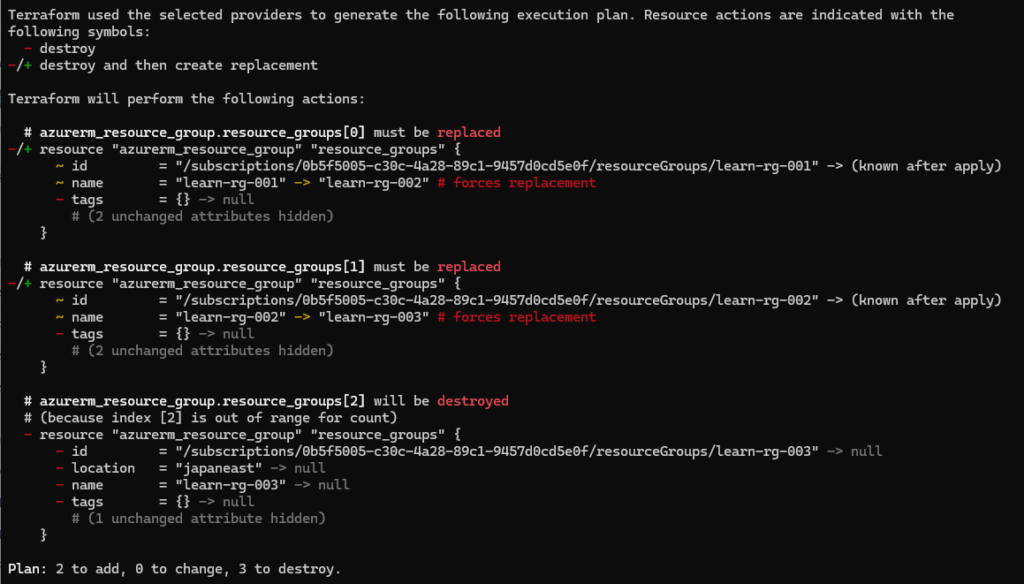
아래의 예제 코드를 이미 배포한 환경에서 learn-rg-001 을 삭제하면 어떻게 될까?
- learn-rg-001 = INDEX.[0]
- learn-rg-002 = INDEX.[1]
- learn-rg-001 = INDEX.[2]
만약 learn-rg-001만을 삭제하고자 리스트에서 이 리소스 그룹의 항목을 주석 처리하거나 제거한다면, Terraform 은 learn-rg-001 이 사라진 것을 감지하고 남은 리소스 그룹의 인덱스를 재조정한다.
learn-rg-001 = INDEX.[0]삭제- learn-rg-002 = INDEX.[0] 재조정
- learn-rg-003 = INDEX.[1] 재조정
인덱스의 재조정으로 인해 Terraform 은 기존의 리소스 그룹을 삭제하고 새로운 인덱스에 맞게 다시 생성한다. 결과적으로 원하지 않게 모든 리소스 그룹이 재생성 (replaced) 된다. 운영중인 환경에서 모든 리소스에 영향이 가는 리스크는 감수할 수 없다.
# Variables
variable "location" {
type = string
default = "japaneast"
}
variable "resource_group_names" {
type = list(string)
default = [
# "learn-rg-001",
"learn-rg-002",
"learn-rg-003"
]
}
# Resource Groups
resource "azurerm_resource_group" "resource_groups" {
count = length(var.resource_group_names)
location = var.location
name = var.resource_group_names[count.index]
}
terraform plan 실행 결과